It is a simple java program that supports you in manually evaluating links between ressources of the semantic web.
Evaluating means that you take a random sample (or all) of a set of links and that you determine for each of those
links if they are correct or incorrect.
It can
load reference data (the links) as ntriples or alignment format
save the evaluated links as ntriples (according to the LATC standards split in positive.nt and negative.nt),
alignment format or as tab separated CSV
work with geocoordinates, calculate and show geographical distances between the two nodes of a link
create a README file with the number of links, sample size, sample precision and date in it
show a graph of precision by confidence cutoff which helps you determine the optimal confidence threshold
Included are also executable classes, scripts and XSLT stylesheets that allow to:
determine the amount of ressources with multiple link partners (high link "polygamy" is an indicator of bad
link- and/or data quality in sameAs links)
convert alignment files to tab separated CSV which helps create random samples
convert ntriples files to csv
Motivation
One of the core aims of the semantic web is to create useful links between already existing ressources. If you
happen to create some of those links, you most probably do it with a tool like Silk that reads in a configuration
file ("link specification") and can potentially create millions of links out of such a link specification. Before
flodding the semantic web with millions of links, it is however a good idea to check if those links are correct in
the first place :-) Often those URIs contain large sequences of seemingly random numbers and do not provide enough
information to know what the URI represents. Manually creating a random sample and then copy-pasting dozens of
URLs into the browser can get tedious however so the Evaluation Tool was created to support the user with that
task.
An examplary link set
Disclaimer
This program was gradually developed as my own tool to help me in my work and is in no way guaranteed to be bug
free or thoroughly optimized for usability or ease of installation. Before you implement such a program yourself
however, I think just using mine may safe you a lot of time and headache should need the same functionality. If
you only need to evaluate a small set of links once it may not be worth it as you need quite a lot of stuff to
execute it, namely svn, maven and java, but if you use it regularily I'm sure it can save you a lot of work. To my
knowledge such a tool does not already exist (if there already is please tell me).
Installation & Execution
Prerequisites
First, you need Subversion, Maven 2 or higher and Java 6 or higher. If you don't have them, you can install them
in Ubuntu with the following commands (although Subversion and Java should already be preinstalled for most
versions):
Note that Maven 3 is already available and backwards compatible so you can install that as well but Maven 2 seems
to be included in the standard package sources for Ubuntu 11.04 and is thus easier to install. For windows I guess
you can find it here:
Subversion
,
Maven 3
and
Java
.
Installation
Go to your favourite directory and then execute:
svn checkout https://saim.svn.sourceforge.net/svnroot/saim/trunk saim
cd saim/saim-core
mvn compile
If you work with very big files you may need
export MAVEN_OPTS=-Xmx2048m
(or some other value) before but in those cases you should probably have set a reasonable
load limit
anyways.
Update
The Evaluation Tool is now developed in
its own project on github
but you should still use the old sourceforge link if you just want to run it. On github, my colleague Mofeed
Hassan is developing a Web Interface for it with a different visualization, so if you want to help out with the
development, create an issue or make a push request there.
Workflow
0. Creating the links
Make sure that you create the links as either ntriples or alignment format. I actually suggest using both, with
the ntriples file containing the links above your chosen thresholds and the alignment file also containing
lowprecision links. This makes it easy to identify the best threshold and reselect the links without the need to
run the matching again. In Silk that may look like this:
In order for your evaluation to be representative, your sample has to be random. If you just want to take a quick
peek at your file you can of course just set the load limit and then load your file but depending on the matching
program used for creating them, the links at the beginning of the file may have totally different properties then
those at the end of the file. And if you want to put your evaluation in a paper it has to be a random sample
anyways.
1.1 With a small linkset
Set the
load limit
to 0 (unlimited) and load your file. It will be automatically shuffled after being loaded. Then, set the load limit
to your desired sample size (e.g. 250) and go to Operations->Shrink to load limit. You now have a random sample
loaded.
1.2 With a big linkset
If your linkset file is hundreds of megabytes in size, the program may crash due to insufficient heap size (a
character in Java is always 16 Bit so a string needs about twice as much memory an equal UFT-8 encoding). While you
you can increase the heap size via
export MAVEN_OPTS=-Xmx2048m
(or more), loading and shuffling still takes a while, so you can speed up the loading with the following:
1.2.1 If the format is ntriples
Most modern linux distributions contain the sort command with the option -R (random). If your sort does not have the
-R option, you need to upgrade your GNU Coreutils. If you don't have the sort command at all, you find it here
for Linux
and here
for Windows
. Now you can just do:
sort -R links.nt -o links.nt
head -yoursamplesize links.nt > sample.nt
And load sample.nt.
1.2.2 If the format is alignment
Because the alignment format is XML based, you cannot just shuffle it directly. Fortunately, the Evaluation Tool
includes an XSLT (XLS Transform) 2.0 Stylesheet named aligntocsv. Unfortunately the Ubuntu standard XSLT processor
xsltproc
is only XSLT 1.0 compatible so you need to install an XSLT 2.0 Processor like
SAXON
. You can then transform the Alignment file to a simple CSV table:
If you don't want to install a XSLT 2.0 processor you also just use your browser because all the modern browsers
have XSLT 2.0 processors included. So in this case you would just prepend the following line to your links.xml file:
sort -R links.csv -o links.csv
head -yoursamplesize links.csv > sample.csv
Now you can load sample.csv via Load->Reference as CSV.
2. Evaluating
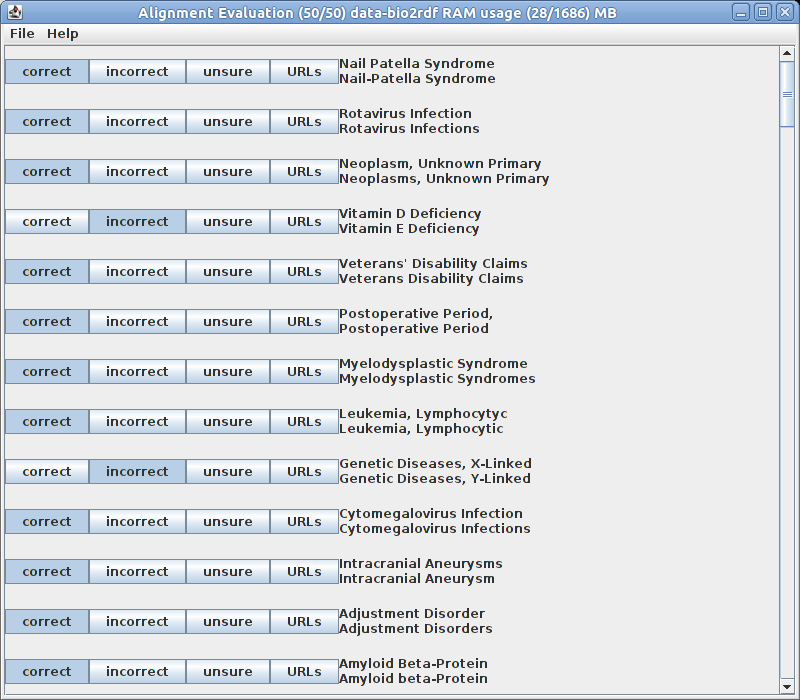
The program should now look like this
After loading and shuffling, the program displays a list of the links together with a few buttons. Initially, only
the urls of the links are displayed but the label thread sequentially loads the representative property (probably
rdfs:label) for each URL from a SPARQL endpoint. If the labels are loaded correctly and display the right property
you can now evaluate all the links with the buttons "correct", "incorrect" and "unsure". The "URLs" button
resolves the urls of a link in the browser and also displays all their triples from the SPARQL endpoint. If the
labels are not properly displayed, you need to...
Configure the name sources
The names source file is located under
saim-core/config/namesources.csv
. You can open it in the program with Options->Edit name source file and when you are finished reload it with
Options->Reload the name source file. On some platforms you may need to edit the file manually, as the program tries
Desktop.edit() first which is not supported by all platforms and then uses "gedit" and if that fails "edit". The
table below shows the structure of the name source file. There are four columns: prefix, property, endpoint and
hasGeoCoordinates.